VÉGÉTAUX  ET PAYSAGE
ET PAYSAGE
Voir les plantes autant que les savoir
Voir les plantes autant que les savoir
Quelques considérations
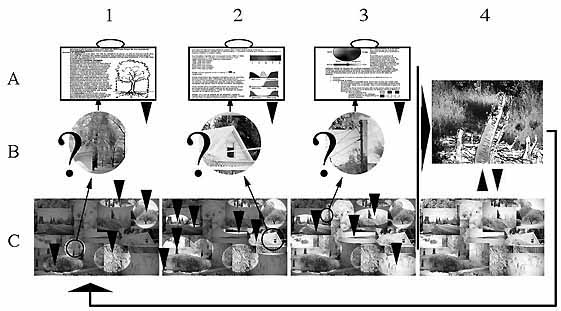
L'ordre a un effet sur l'efficacité d'utilisation de l'information
Dans chaque projet nous traitons de nombreuses images. L'ère de l'informatique ajoute un supplément de complexité à la gestion de nos images.
Voici les bases pour réfléchir au problème de classement des images.
La copie est la force de l'informatique
Il faut en premier lieu comprendre qu'il faut gérer deux entités distinctes: les vraies photographies (diapos, papier, cartes postales...) et leurs doubles informatiques (images numérisées). Il n'y a qu'un seul original mais il peut y avoir plusieurs doubles (imagette, image à 75dpi, image à 300dpi, extrait)
La correspondance entre les différentes représentations et l'original doit être garantie par une identité partielle de nom ou une table de correspondance. L'identité de nom facilite le travail. Seul la partie du nom permettant le rangement doit être identique, la partie descriptive de la copie doit varier. L'original a préséance sur ses doubles pour fixer le nom commun à tous.
Index le doigt
Le nom du fichier ne peut pas contenir tous les éléments qui seront utiles pour retrouver rapidement les images. Il faut donc accompagner les images d'un index descriptif.
Pointer du doigt autre chose est d'une simplicité remarquable mais également un grand risque. Les pointeurs sont la plus grande source des bugs de l'informatique.
Ne jamais surcharger les baudets, ils n'apprécient pas
Pour garder une bonne vivacité d'accès aux images, il faut éviter de dépasser la centaine d'images par répertoire. Une vingtaine est l'idéal.
Ce n'est pas parce que les ordinateurs vont de plus en plus vite qu'on ne doit pas faire attention. La dimension est liée à la vitesse. C'est vrai dans de nombreux domaines et cela se vérifie rapidement en informatique.
Pas toujours facile de prévoir le développement des situations
Il faut savoir si la base d'image devra pourvoir servir à d'autres études plus tard. (Classification définitive ou classification pour le projet).
Si la classification est définitive, le descripteur du nom de fichier doit être universel. L'ordre chronologique est alors le meilleur système. Il permet de structurer les dossiers par années, par mois et éventuellement plus (jour, heure, minute, seconde) en cas de très grosse base de donnée. Dans un classement permanent, il faut éviter les systèmes à deux entrées (et plus) par exemple temps et lieu car il y aura ambiguïté dans l'utilisation. Les entrées autres que celles de la structure de stockage se feront par des index. Il peut y avoir autant d'index que de thèmes intéressant l'étude et toute nouvelle étude pourra ajouter des index sans modifier la base de stockage.
Si la base est détruite ou gelée après l'étude, il vaut mieux utiliser une entrée par thesaurus. C'est à dire une structure hiérarchique des thèmes et des sous thèmes de l'étude. Cette structure a comme implicite que le thesaurus soit établi à priori et ne permet pas d'y revenir en cours d'étude. C'est la structure du thesaurus reprise dans les répertoires et sous-répertoires qui sert d'index aux images. Dans mon expérience, le classement par thesaurus ne fait gagner du temps et du confort que pour les études très courtes sur des thèmes anormaux par rapport au travail ordinaire. Le temps gagné au départ à ne pas faire les index est reperdu à refaire de nouvelles images à chaque étude. (C'est aussi un concept de pollution que ma morale écologique réprouve.)
Ce n'est pas une obligation mais c'est pratique
Pour classer et retrouver rapidement une image dans un dossier il faut que le nom de fichier comporte les indications de la structure hiérarchique des dossiers dans lesquels il est rangé. Par exemple A/2000/05/A200005cb12.jpg où cb12.jpg est le nom spécifique du fichier et A200005 la partie de son nom qui correspond à la structure de rangement.
Le nom spécifique du fichier peut comprendre un simple numéro d'ordre. Il faut alors préférer un nombre avec une structure fixe ou les 0 servent au remplissage ex 002 pour que l'ordinateur classe les fichiers dans le bon ordre. Il peut aussi comprendre des indications avec des lettres pour faciliter le repérage.
Encore un truc pratique
Pour faciliter le rangement des originaux et des doubles, il y a intérêt à les mettre dans une structure parallèle. Cette similitude permet à la fois des réflexes d'utilisation et l'automatisation de certaines tâches.
original/2000/05/200005cb12.jpg imagettes/2000/05/A200005cb12.jpg pour-ecran/2000/05/B200005cb12.jpg avant-projet/2000/05/C200005cb12bleu.jpg
Le doigt doit pointer vers quelque chose
Le nom de fichier ne suffit pas à connaître son contenu, il faut au moins un fichier de référence qui dit ce qui est pointé par l'index. Le minimum et le plus pratique est une liste où chaque nom de fichier est associé à un texte sur son contenu qui répond aux questions qui? quoi? où? quand? et éventuellement plus. Exemple:
200005cb12.jpg - Le pont Jacques Cartier vu depuis la Ronde 12 mai 2000 lumière bleuté du matin
Les mots dans cet index descriptif sont important car ce sont eux qui seront retrouvés dans les outils de recherche en plein texte.
Lorsque le domaine de connaissance est déjà bien établi et que les types d'utilisation sont aussi répertoriés, une base de donné avec des mots clefs permet un accès plus rapide au contenu, ils sont indispensables pour les très grosses banques d'images ou si des calculs sur la banques d'image doivent être effectués.
Une planche contact des photos est très utile pour revoir les images en laissant travailler sa sensibilité simplement guidé par une intuition vague.
Des outils automatiques sont utiles pour générer ces planches. La mise en fichier html des imagettes est aussi une bonne solution car elle permet de créer plusieurs index visuels sans nouvelle fabrication d'images. (voir exemple par date et par sujet)
Les fichiers html permettent de visualiser texte et images de la base en organisant le texte indépendamment du stockage des images. Chaque nouveau fichier peut donc restructurer les images et leurs légendes à sa façon, voir le monde d'un œil nouveau. L'immense avantage est que les images ne sont pas dupliquées. Elles n'existent physiquement qu'une seule fois dans l'ordinateur mais peuvent apparaître à de nombreux endroits et dans de nombreux textes différents. Une personne peut donc travailler l'image du projet pendant que d'autres travaillent sur les textes du projet dans différentes possibilités d'interprétation de cette image.
 |